

Understanding AdaBoost: Adaptive Boosting in Machine Learning
Introduction
AdaBoost is an example of an ensemble supervised Machine Learning model. It consists of a sequential series of models, each one focussing on the errors of the previous one, trying to improve them. The most common underlying model is the Decision Tree, other models are however possible. In this post, we will introduce the algorithm of AdaBoost and have a look at a simplified example for a classification task using sklearn. For a more detailed exploration of this example – deriving it by hand – please refer to AdaBoost for Classification – Example. A more realistic example with a larger dataset is provided on kaggle.
AdaBoost, short for Adaptive Boosting, is a powerful ensemble learning technique used widely in the field of machine learning. Ensemble learning combines the predictions of multiple models, known as weak learners, to create a more robust and accurate final model. In AdaBoost, these weak learners are iteratively improved by adjusting their weights based on their performance, ultimately leading to a strong model that performs well on complex tasks.
AdaBoost is particularly effective for both classification and regression problems. When applied to regression tasks, AdaBoost uses the AdaBoostRegressor class, which is designed to handle the nuances of continuous output prediction. This article delves into the details of AdaBoostRegressor, exploring its functionality, how to implement it, and methods to speed up its performance (高速化). We will also cover the process of preparing data, defining the model, making predictions, and evaluating accuracy.
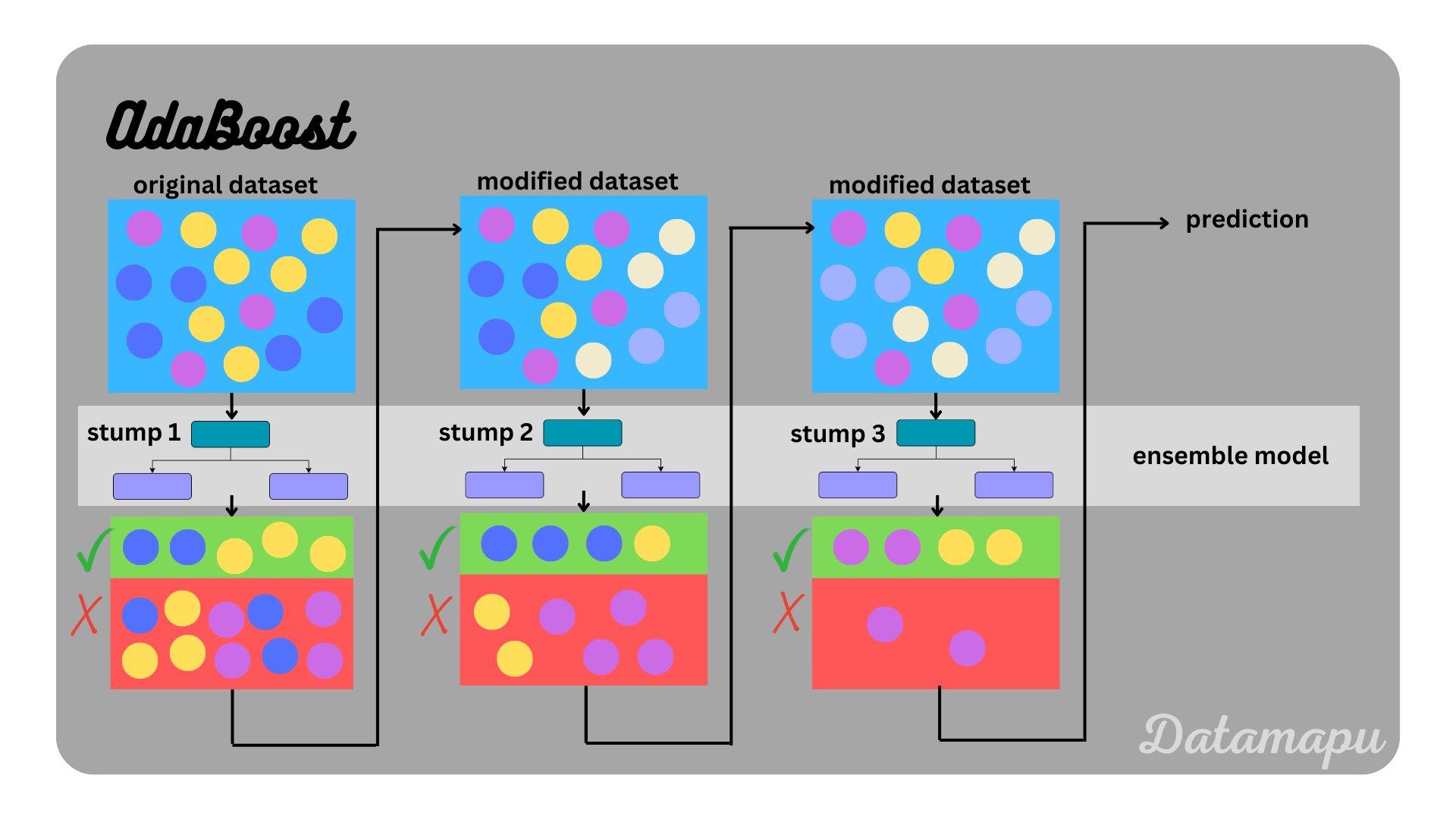
The Core Principle of AdaBoost
The essence of AdaBoost lies in its ability to “boost” weak learners. A weak learner is typically a model that performs slightly better than random guessing. By combining multiple weak learners, each focusing on different aspects of the data, AdaBoost creates a strong learner capable of making accurate predictions. The process involves assigning higher weights to incorrectly predicted instances, thereby forcing subsequent models to focus on the more challenging cases.
Preparing Data for AdaBoostRegressor
Data Preprocessing: A Crucial Step
Before implementing AdaBoostRegressor, it’s essential to ensure that your data is well-prepared. Data preprocessing includes cleaning, transforming, and normalizing the dataset to make it suitable for training the model. The quality of the input data directly impacts the performance of the AdaBoostRegressor.
- Handling Missing Values: Missing data can lead to inaccuracies in predictions. Techniques such as imputation or removing records with missing values can be employed.
- Encoding Categorical Variables: If your dataset contains categorical features, they need to be encoded into numerical values using techniques like one-hot encoding or label encoding.
- Feature Scaling: Normalizing the data ensures that all features contribute equally to the model. Techniques like Min-Max scaling or Standardization can be applied.
Splitting the Dataset: Training and Testing
Once the data is preprocessed, the next step is to split it into training and testing sets. This ensures that the model is evaluated on unseen data, providing a more accurate measure of its performance.
- Training Set: This portion of the data is used to train the model.
- Testing Set: This portion is used to evaluate the model’s performance after training.
A common practice is to split the data in an 80-20 or 70-30 ratio, depending on the size of the dataset.
The Algorithm
The name AdaBoost is short for Adaptive Boosting, which already explains the main ideas of the algorithm. AdaBoost is a Boosting algorithm, which means that the ensemble model is built sequentially and each new model builds on the results of the previous one, trying to improve its errors. The developed models are all weak-learners, that is they have low predictive skill which is only slightly higher than random guessing. The word adaptive refers to the adaption of the weights that are assigned to each sample before fitting the next model. The weights are determined in such a way that the wrongly predicted samples get higher weights than the correctly predicted samples. In more detail, the algorithm works as follows.
- Fit a model to the initial dataset with equal weights. The first step is to assign a weight to each sample of the dataset. The initial weight is
- 1N
- , with
- N
- being the number of data points. The weights always sum up to
- 1.
- Because in the beginning, all weights are equal, this means they can be ignored in this first step. If the base model is a Decision Tree, the weak learner is a very shallow tree or even only the stump, which refers to the tree that consists only of the root node and the first two leaves. How deep the tree is developed is a hyperparameter, that needs to be set. If we fit an AdaBoost algorithm in Python and use sklearn the default setting depends on whether a classification or a regression is considered.
Defining the AdaBoostRegressor Model
Initializing the AdaBoostRegressor
The AdaBoostRegressor is a class provided by the scikit-learn library in Python. It can be initialized with various parameters that control the behavior of the boosting process.
python
Copy code
from sklearn.ensemble import AdaBoostRegressor
from sklearn.tree import DecisionTreeRegressor
# Initialize base regressor
base_regressor = DecisionTreeRegressor(max_depth=3)
# Initialize AdaBoostRegressor
adaboost_regressor = AdaBoostRegressor(base_estimator=base_regressor, n_estimators=50, learning_rate=1.0)
In the above code:
- base_estimator: This parameter specifies the weak learner to be used. A common choice is DecisionTreeRegressor.
- n_estimators: This defines the number of weak learners to be combined. Increasing this value can improve the model’s performance but also increases computation time.
- learning_rate: This parameter controls the contribution of each weak learner to the final model. A smaller learning rate requires more estimators for good performance.
AdaBoost and Scikit-Learn
Scikit-Learn provides ensemble methods using a Python machine learning library that implements AdaBoost. AdaBoost can be used both for classification and regression problems, so let’s look into how we can use Scikit-Learn for these types of problems.
The aim of the AdaBoost classifier is to start off with fitting a classifier on the original dataset for the task at hand and then fit additional classifiers where the weights of incorrectly classified instances are adjusted.
Hyperparameter Tuning for Optimal Performance
To achieve the best results, it’s essential to tune the hyperparameters of the AdaBoostRegressor. Grid Search or Random Search techniques can be used to find the optimal combination of parameters.
- Grid Search: This method involves testing all possible combinations of a set of hyperparameters.
- Random Search: This method randomly samples from a range of hyperparameters, which can be more efficient than Grid Search.
Choosing the Right Base Estimator
The choice of the base estimator significantly impacts the performance of the AdaBoostRegressor. Decision trees are commonly used as base estimators due to their simplicity and ability to capture complex patterns in the data. However, other models like linear regressors or support vector regressors can also be used, depending on the specific problem at hand.
Training the AdaBoostRegressor
Fitting the Model to the Data
Once the AdaBoostRegressor is defined, the next step is to train it using the training dataset. The fit() method is used to accomplish this.
python
Copy code
# Fit the AdaBoostRegressor to the training data
adaboost_regressor.fit(X_train, y_train)
During training, the AdaBoostRegressor iteratively adjusts the weights of the training instances based on the errors made by the previous weak learners. This process continues until the specified number of estimators is reached or until no further improvement is observed.
Evaluating Training Progress
Monitoring the progress of the training process is crucial to ensure that the model is learning effectively. This can be done by evaluating the performance on the training set after each iteration. If the model starts to overfit, early stopping techniques can be applied to prevent overfitting.
Predicting with AdaBoostRegressor
Making Predictions on New Data
Once the model is trained, it can be used to make predictions on new, unseen data. The predict() method is employed for this purpose.
python
Copy code
# Predict using the AdaBoostRegressor
y_pred = adaboost_regressor.predict(X_test)
The predicted values can then be compared with the actual values in the test set to assess the model’s performance.
Evaluating Model Accuracy
Accuracy in regression tasks is often measured using metrics like Mean Absolute Error (MAE), Mean Squared Error (MSE), and R-squared. These metrics provide insights into how well the model is performing.
python
Copy code
from sklearn.metrics import mean_squared_error, r2_score
# Calculate Mean Squared Error
mse = mean_squared_error(y_test, y_pred)
# Calculate R-squared
r2 = r2_score(y_test, y_pred)
- Mean Squared Error (MSE): This measures the average squared difference between the predicted and actual values. Lower MSE indicates better accuracy.
- R-squared: This metric indicates the proportion of the variance in the dependent variable that is predictable from the independent variables. A higher R-squared value signifies a better fit.
Speeding Up AdaBoostRegressor (高速化)
Strategies for Faster Training
Training an AdaBoostRegressor can be time-consuming, especially with large datasets or a high number of estimators. However, several strategies can be employed to speed up the process:
Parallel Processing: Leveraging multi-core CPUs or GPUs can significantly reduce training time. The n_jobs parameter in AdaBoostRegressor can be set to utilize multiple cores.
python
Copy code
adaboost_regressor = AdaBoostRegressor(base_estimator=base_regressor, n_estimators=50, learning_rate=1.0, n_jobs=-1)
- Reducing the Number of Estimators: While more estimators typically lead to better performance, they also increase computation time. A balance needs to be struck between accuracy and speed.
- Using Stochastic Boosting: Instead of using all the data points at each iteration, stochastic boosting randomly selects a subset of data, reducing training time while still maintaining good accuracy.
- Optimizing the Base Estimator: Simplifying the base estimator, such as using shallower trees in a decision tree regressor, can also speed up the training process.
Reducing Prediction Time
In addition to speeding up training, it’s also important to consider the prediction speed, especially in real-time applications. Here are some strategies:
- Pruning Weak Learners: After training, it may be possible to prune the ensemble by removing weak learners that contribute little to the final model. This reduces the complexity and speeds up predictions.
- Quantization of Predictions: For large-scale deployment, quantizing the predictions can reduce the computation needed for inference, thereby speeding up the prediction process.
Memory Optimization
Managing memory usage is crucial when dealing with large datasets or complex models. Some techniques include:
- Sparse Data Representation: If your dataset is sparse, using sparse matrix representations can significantly reduce memory usage.
- Feature Selection: Reducing the number of features through techniques like PCA (Principal Component Analysis) or regularization can decrease memory usage and speed up both training and prediction.
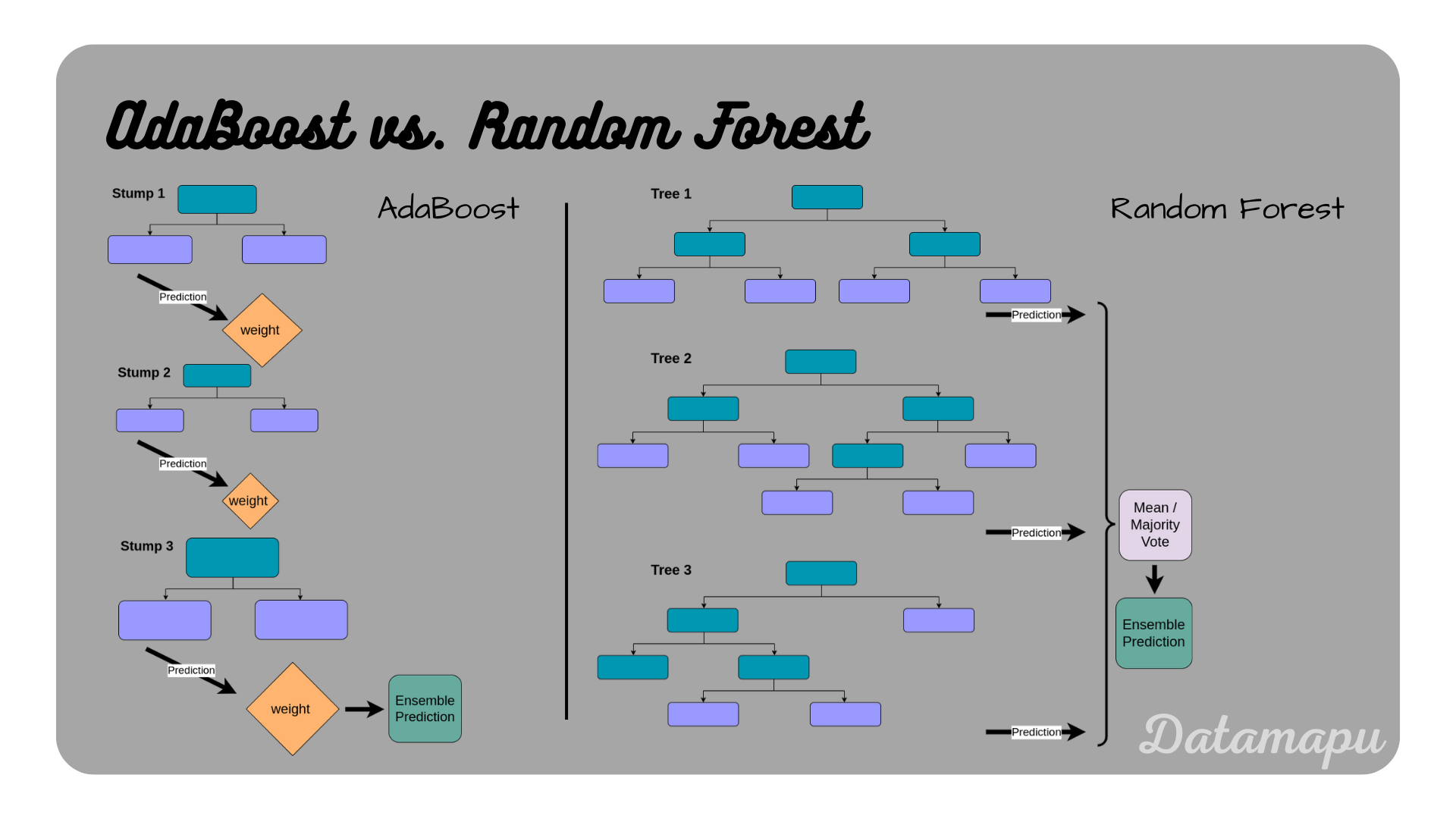
AdaBoost vs. Random Forest
As mentioned earlier the most common way of constructing AdaBoost is using Decision Trees as underlying models. Another important ensemble machine learning model based on Decision Trees is the Random Forest. While Decision Trees are powerful machine learning algorithms, one of their major disadvantages is that they tend to overfit. Both, Random Forest and AdaBoost try to improve this while maintaining the advantages of Decision Trees, such as their robustness towards outliers and missing values. Both algorithms, however, differ substantially. In Adaboost, the weak learners associated are very short trees or even only the root node and the first two leaves, which is called the tree stump, whereas, in a Random Forest, all trees are built until the end. Stumps and very shallow trees are not using the entire information available from the data and are therefore not as good in making correct decisions. Another difference is, that in a Random Forest, all included Decision Trees are built independently, while in AdaBoost they build upon each other and each new tree tries to reduce the errors of the previous one. In other words, a Random Forest is an ensemble model based on Bagging, while AdaBoost is based on Boosting. Finally, in a Random Forest all trees are equally important, while in AdaBoost, the individual shallow trees / stumps have different influences because they are weighted differently. The following table summarizes the differences between Random Forests and AdaBoost based on Decision Trees.
Best Practices for Using AdaBoostRegressor
Ensuring Model Robustness
To ensure the robustness of your AdaBoostRegressor model, it is important to validate its performance across different subsets of data. Cross-validation is a common technique used to assess how well the model generalizes to new data.
- K-Fold Cross-Validation: This involves splitting the data into k subsets, training the model on k-1 subsets, and validating it on the remaining subset. The process is repeated k times, with each subset used once as the validation set.
- Stratified Sampling: In cases where the data is imbalanced, stratified sampling ensures that each fold in cross-validation has a similar distribution of the target variable, leading to more reliable performance metrics.
Summary
AdaBoost is an ensemble model, in which a sequential series of models is developed. Sequentially the errors of the developed models are evaluated and the dataset is modified such that a higher focus lies on the wrongly predicted samples for the next iteration. In Python, we can use sklearn to fit an AdaBoost model, which also offers some methods to explore the created models and their predictions. It is important to note, that different implementations of this algorithm exist. Due to this and the randomness in the bootstrapping, there are some differences, when we compare the details to the model fitted using sklearn. The example used in this article was very simplified and only for illustration purposes.
1 Comment
Pingback: Gboyega Ebenezer Adebami Que Es: A Legacy Of Innovation And Leadership » Bloghives